Scrape Twitter data for free
Ever wondered if it was possible to scrape Twitter data without using their super expensive API? Well, it is and it has been possible for a while now, the only issue is scalability which won't really be a problem for most people. I'll still go through some ways to make it more scalable. Let's dive in.
How?
While everyone always tries to use the official Twitter Developer API, there's actually a better and free alternative to scrape all the info you need. If you check network requests while using the Twitter website, you'll see that every time you perform an action, it calls their GraphQL API. For example, if you click on a tweet, you'll see a request similar to this one
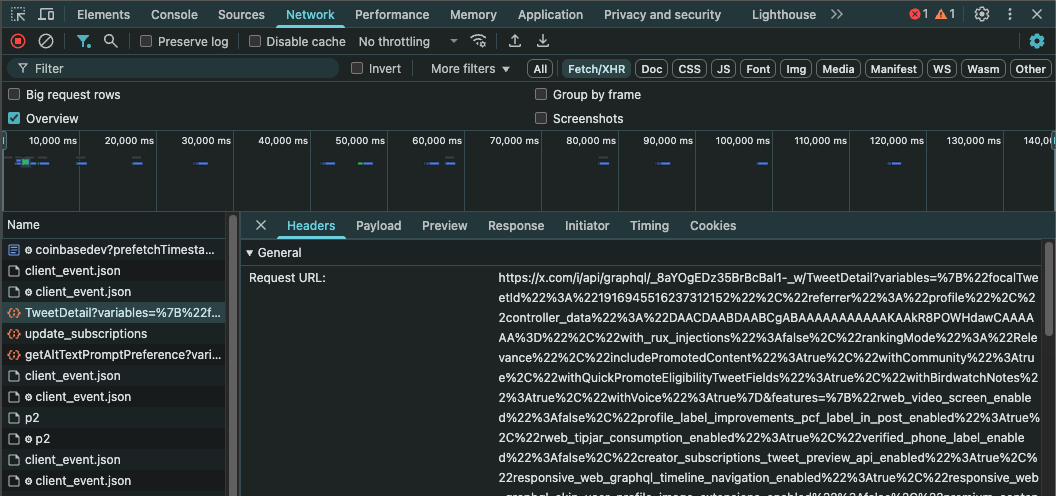
That ugly and long GET request is what contains all the data you need. Now let's analyze it and see how it can be replicated.
Analyzing the request
First of all, let's start with the base url, which is the following
# Base url
baseUrl = "https://x.com/i/api/graphql"Now what we need is the GraphQL ID of the function we want to call, you can find it by just performing the action on the website and then checking the request again. Right after the GraphQL ID we'll find the function name
# gql ID / function name
gqlId = "_8aYOgEDz35BrBcBal1-_w/TweetDetail"Moving forward, we'll need to find the query params that are sent in the request. If we move to the "Payload" tab of the request in the chrome dev tools, and we click "view-decoded", we can see the actual params in a more readable way since earlier we were viewing them as an url encoded string. You will see 3 different objects, the first one being "variables", which is the most essential one given that it contains the tweet id in this case.
# variables object
variables = {
"focalTweetId":"1650953166135914526",
"referrer":"profile",
"with_rux_injections":False,
"rankingMode":"Relevance",
"includePromotedContent":True,
"withCommunity":True,
"withQuickPromoteEligibilityTweetFields":True,
"withBirdwatchNotes":True,
"withVoice":True
}If you're calling other functions, you might have different param fields (instead of focalTweetId for example). You might also find a value named "controller_data" which is not really needed and you can ignore it. The second object you'll find is the "features" object, which contains a lot of different and kinda useless flags. You shouldn't really care about the values in this object but it's still needed for the request to work.
# features object
features = {
"articles_preview_enabled": False,
"c9s_tweet_anatomy_moderator_badge_enabled": True,
"communities_web_enable_tweet_community_results_fetch": True,
"creator_subscriptions_quote_tweet_preview_enabled": False,
"creator_subscriptions_tweet_preview_api_enabled": True,
"freedom_of_speech_not_reach_fetch_enabled": True,
"graphql_is_translatable_rweb_tweet_is_translatable_enabled": True,
"longform_notetweets_consumption_enabled": True,
"longform_notetweets_inline_media_enabled": True,
"longform_notetweets_rich_text_read_enabled": True,
"responsive_web_edit_tweet_api_enabled": True,
"responsive_web_enhance_cards_enabled": False,
"responsive_web_graphql_exclude_directive_enabled": True,
"responsive_web_graphql_skip_user_profile_image_extensions_enabled": False,
"responsive_web_graphql_timeline_navigation_enabled": True,
"responsive_web_media_download_video_enabled": False,
"responsive_web_twitter_article_tweet_consumption_enabled": True,
"rweb_tipjar_consumption_enabled": True,
"rweb_video_timestamps_enabled": True,
"standardized_nudges_misinfo": True,
"tweet_awards_web_tipping_enabled": False,
"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled": True,
"tweet_with_visibility_results_prefer_gql_media_interstitial_enabled": False,
"tweetypie_unmention_optimization_enabled": True,
"verified_phone_label_enabled": False,
"view_counts_everywhere_api_enabled": True,
"responsive_web_grok_analyze_button_fetch_trends_enabled": False,
"premium_content_api_read_enabled": False,
"profile_label_improvements_pcf_label_in_post_enabled": False,
"responsive_web_grok_share_attachment_enabled": False,
"responsive_web_grok_analyze_post_followups_enabled": False,
"responsive_web_grok_image_annotation_enabled": False,
"responsive_web_grok_analysis_button_from_backend": False,
"responsive_web_jetfuel_frame": False,
}The last object is also basically useless and it's called "fieldToggles"
# fieldToggles object
fieldToggles = {
"withArticleRichContentState":True,
"withArticlePlainText":False,
"withGrokAnalyze":False,
"withDisallowedReplyControls":False
}Replicating the request
Our final request url will look something like this
import urllib.parse
request_url = f"{baseUrl}/{gqlId}?{urllib.parse.urlencode({'variables': json.dumps(variables, separators=(',', ':')), 'features': json.dumps(features, separators=(',', ':')), 'fieldToggles': json.dumps(fieldToggles, separators=(',', ':'))})}"Now comes the interesting part. Looks too easy right? Unfortunately, to make sure the request is sent correctly, we'll need a valid Bearer token (cookie that identifies the user).
How?
First of all, there were limits set on their backend, so i couldn't use just one wallet. Given that, i proceeded to create hundreds of wallets, fund them and send them some useless NFTs that had to be sent in the request in order to claim the real NFT. The other big problem was that they announced the drop day, but not the time. So i had to implement a monitoring system that would ping their servers every 10000ms in order to know if the faucet was open or not. Now onto the actual code
After initializing the instance, i had to implement the monitor and claim logic. For the monitor, the idea was to send random params just to see the response status code and check if the faucet was open or not.
The startClaim() function would then initialize the actual claim with real params, invoking the function for every wallet i prepared (twice per wallet since the limit was 2 per wallet).
Results
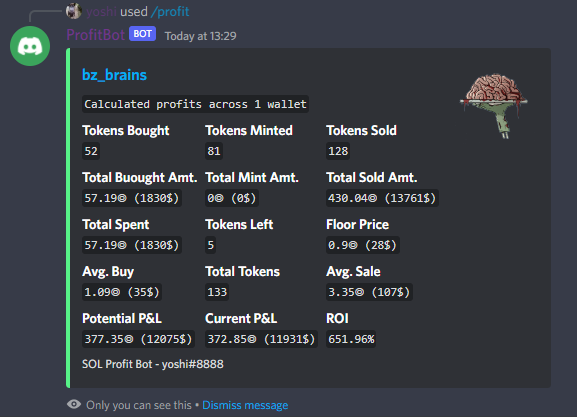
At the end of the drop, i claimed almost every single NFT available, while manual users were rightfully complaining (best part lol). I claimed 81 NFTs for free in total and I had also bought some on the secondary market before. As you can see in the pic below, i made some really nice profits by taking advantage of the lack of expertise of the devs (note that $SOL was trading at ~$30$ at the time)